
Multimodal large language models (MLLMs) are predominantly evaluated on free-form vision–language tasks such as visual question answering, captioning, and summarization. However, their practical use is rapidly expanding to more structured computer vision settings, where users prompt models to perform localization-centric tasks such as object detection, often within larger agentic or decision-making systems. Despite this shift, there is currently no standardized benchmark that systematically evaluates these capabilities at scale.
In this work, we introduce the first comprehensive benchmark specifically designed to assess the promptable localization abilities of generalist MLLMs. Our benchmark spans four core task categories: object detection, referring expression detection, instance-level detection, and video-based detection. To enable consistent and fair evaluation, we develop a unified framework that standardizes inputs, enforces parsable bounding box outputs, and defines transparent evaluation protocols across tasks.
Using this suite, we evaluate a diverse set of open-source and proprietary MLLMs, providing an in-depth analysis of their performance and limitations. Beyond accuracy, we examine models’ ability to adhere to output format specifications, showing that current systems are highly sensitive to formatting constraints and often fail to generalize even to minor variations. Our results highlight both the strengths and shortcomings of state-of-the-art MLLMs in localization settings, and point toward important directions for improving multimodal model design and evaluation.
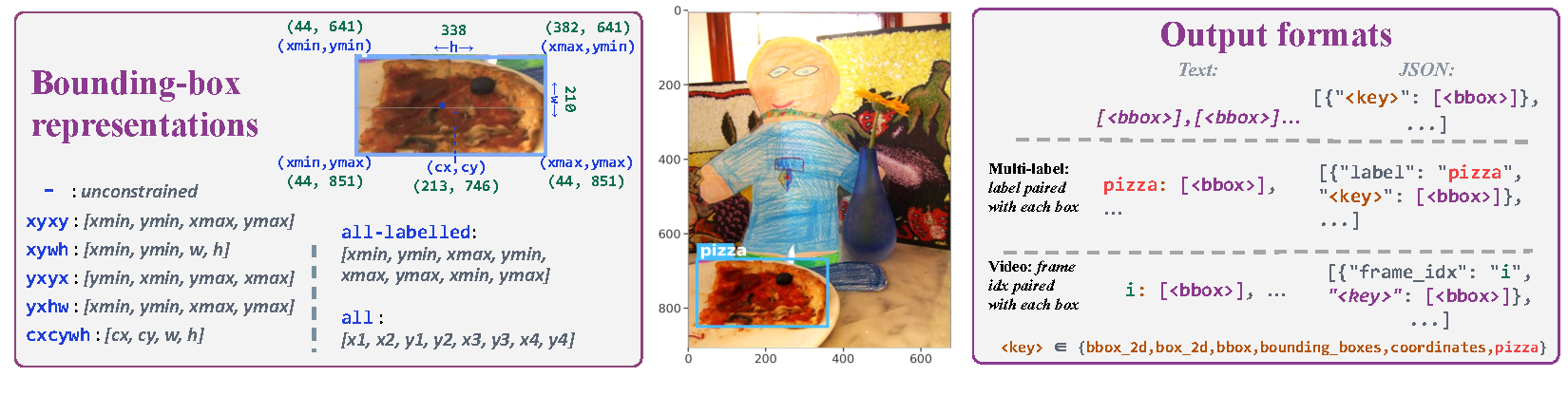
FindIt is structured as a grid over three axes: task & data, bounding-box representation, and output format. Each model is reported at the combination that maximises its average F1@0.5.
Object Detection
Single- and multi-label detection using class names as queries.
Referring Expression Detection
Localize objects described by free-form natural language.
Instance Detection
Localize a specific instance given a visual support image.
Video Object Detection
Object and instance localization extended to multi-frame inputs.
We vary the bounding-box representation across seven types spanning corner-based, center-with-size, and four-corner formats, plus an unconstrained condition. We evaluate both plain text and JSON output modes, with variations covering single-label, multi-label, and multi-frame inputs as well as different JSON key choices.
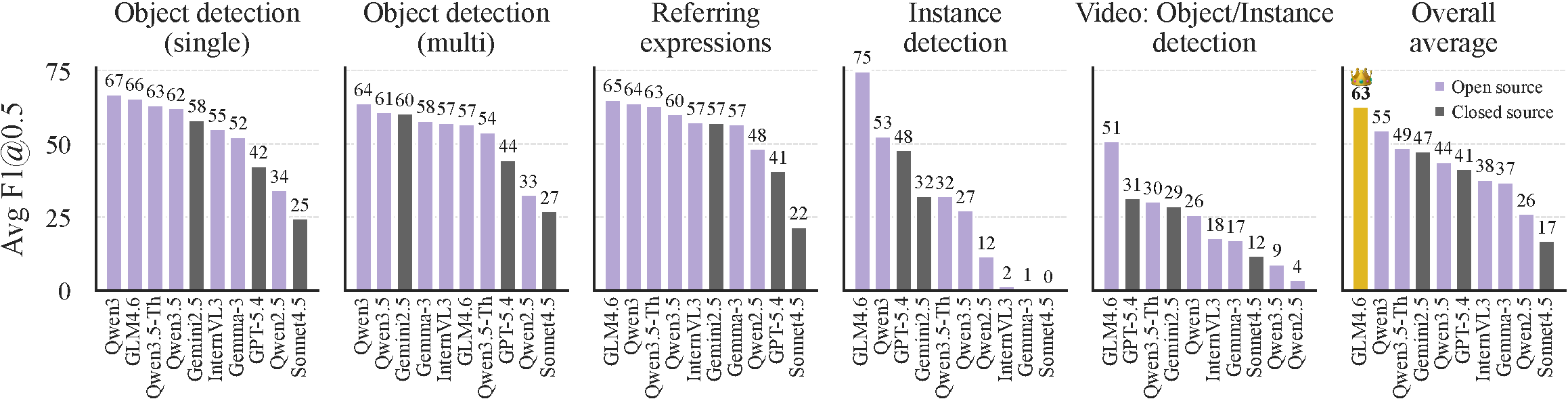
We report cross-task performance averaged over all tasks, using the best output-format configuration found per model. GLM-4.6V achieves the highest overall scores, driven primarily by its strong performance on instance detection tasks.
A central finding of FindIt is that a model’s score depends as much on output format as on grounding ability. We examine two axes: bounding-box representation and structured output format (text vs. JSON).
xyxy, yxyx for Gemma and Gemini 2.5 Flash,
and xywh for GPT-5.4 and Sonnet 4.5 in JSON.
Switching from the best to the second-best format collapses both mIoU and F1 on
open-source models. cxcywh, all, and
all-labelled fail for open-source models, with most F1 below 5.
cxcywh, every open-source model scores near-zero
F1 using the prompted cxcywh during parsing — but parsing the same outputs
as the model’s preferred corner format recovers 50–75 F1.
This indicates that most models specialize in one preferred format and will output
this format independent of the given prompt instructions.
xyxy,
xywh, yxyx, and yxhw at 100 %
adherence, with F1 between 32 and 42 across the four standard bbox formats.
Its best result is still below Qwen3-VL and Gemini 2.5 Flash at
their preferred formats.
@article{khandelwal2026findit,
title = {FindIt: A Format-Informed Visual Detection Benchmark
for Generalist Multimodal {LLMs}},
author = {Khandelwal, Eshika and Pan, Jingjing and Zhang, Mingfang
and Kong, Quan and Garattoni, Lorenzo and Kuehne, Hilde},
journal = {arXiv},
year = {2026}
}